
Introdução
Em 2014 um grupo de desenvolvedores criou um manifesto que buscava definir o que as aplicações precisavam para que fossem consideradas reativas. Abaixo eu listo basicamente o que esses desenvolvedores definiram como aplicação reativa.
Manifesto Reativo
- Responsividade (responsiveness);
- Resiliência (resilience);
- Elasticidade (elasticity);
- Guiado por mensagens (message driven).
Apesar de existirem esses conceitos definidos no manifesto reativo, com falei acima este conceito está mais ligado a uma aplicação em seu contexto geral, veremos algo mais voltado ao contexto de aplicações back-end e entender onde a “reatividade entra” de fato nessa história.
A moda da vez, programação reativa, o que é isso?
No Spring 5 tivemos a introdução da programação reativa, que utiliza um modelo de programação assíncrona para dar suporte a chamadas de Input/Output (I/O) de dados de maneira não bloqueante.
Essa “nova forma de programar” torna as aplicações altamente escaláveis, assim conseguimos ter suporte ao processamento de uma grande quantidade de requisições quando comparamos aplicações reativas a aplicações não reativas.
Para ser possível essa alta capacidade de processamento, a programação reativa tentou maximizar o uso de CPU ao longo do tempo em quê uma requisição fica sob domínio do processamento do servidor Web, tudo isso através de uma melhor gestão de threads e seus recursos como veremos mais abaixo.
Processos e Threads
Todo esse modelo de enfileiramento de requisições para realizar o processamento de operações depende dos recursos disponíveis para que isso aconteça. Esses recursos são gerenciados pelo Sistema Operacional (SO), tudo isso utilizando do conceito de processos e threads.
Quando precisamos recuperar algo de um banco ou realizarmos uma chamada de rede para outra aplicação nós realizamos uma operação de I/O que o SO gerencia através de processos e/ou threads. Assim, mesmo que um computador tenha uma única CPU, o SO faz parecer que temos várias pois cada um dos processos e threads ficam intercalando o uso dessa CPU dando assim a ilusão de que o computador está fazendo várias coisas ao mesmo tempo, sendo que na verdade o SO apenas está dando acesso a sua CPU a cada processo/threads um pouco de tempo por vez.
Para complementarmos o nosso entendimento a respeito de processos e threads é legal também entendermos a diferença entre esses dois. Basicamente a diferença aqui é que um processo pode ter várias threads que compartilham uma mesma memória, enquanto que o processo não consegue ter acesso a memória de outro, essa é a principal diferença.
Certo, agora temos o entendimento de processos e threads, ok?! O que mais precisamos saber? Bem, existem cálculos quê, mesmo sabendo que a CPU consegue intercalar tão bem processos e threads, a CPU acaba ainda assim ficando ociosa vez ou outra! E geralmente isso está atrelado a uma operação que ocorre em específico! É o famoso I/O!!! Falaremos dele a seguir.
O que é Input/Output de dados bloqueante?
Como vemos abaixo, os processos e threads podem ter três estados:
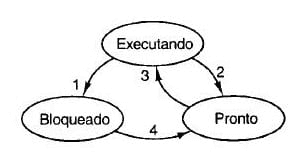
Mas vamos entender com mais detalhes o que é cada um dos estados abaixo:
- Executando: o processo e/ou thread está realmente usando a CPU para realizar o processamento de uma requisição;
- Pronto: semelhante ao estado acima, nesse estado o processo e/ou thread está pronto para execução mas não tem CPU disponível no momento para conseguir continuar com o seu processamento;
- Bloqueado: nesse estado o processo e/ou thread não é capaz de seguir com sua execução até que um evento externo aconteça, entre esses eventos nós podemos citar uma chamada de rede ou uma leitura de disco.
Acima eu sempre falo de "processo e/ou thread" pois dentro do contexto de sistemas operacionais esses estados são os mesmos para os dois.
Agora que já sabemos o que é o estado bloqueado de um processo e/ou thread vamos entender o que é o I/O bloqueante e o não bloqueante.
I/O bloqueante e não bloqueante
Abaixo veremos elencadas uma lista de características de cada uma dessas formas de programar.
Bloqueante:
- Requisições enfileiradas;
- Necessário o processamento de uma a uma por completo antes de deslocar a thread para processar outra requisição;
- A requisição mais nova só será processada ao fim da anterior;
- Esquema de programação mais fácil, geralmente é mais utilizado por esse motivo também.
Não bloqueante:
- A requisição mais nova poderá ser processada (ou parte dela) antes que todas a requisição que o servidor recebeu sejam processadas;
- Se uma requisição estiver esperando o I/O outra poderá ser processada mesmo assim;
- A ordem de chegada e processamento nem sempre é mantida;
- Capacidade de processar muitas requisições simultaneamente;
- Esquema de programação complexa, um pouco mais difícil de entender, debugar e programar.
Observe que uma das características acima está em negrito, isso pois é um detalhe importante por essa característica ter tudo a ver com dois pontos do manifesto reativo: responsividade e resiliência. Por qual motivo? Vamos lá:
- Responsividade: requisições mais simples podem ser processadas mais rapidamente, não precisando esperar o processamento de uma requisição mais complexa que chegou primeiro, por exemplo;
- Resiliência: mesmo que uma outra requisição demore mais que o normal ou falhe no seu I/O ela não impactará negativamente outra requisição (resiliência).
Bem, imagino que esse seja também um dos motivos pelo qual a programação não bloqueante no contexto de processamento de requisições Web geralmente é chamada de "programação reativa" 😉.
Agora que já sabemos o que é o tal do processo e/ou thread bloqueado, características tendo em vista os modelos de programação bloqueante e não bloqueante e outras coisas mais, vamos ver como funciona isso em uma framework de desenvolvimento web.
Modelo síncrono, uma requisição, uma thread!
Até agora no nosso artigo veja que não falamos de nenhuma tecnologia, linguagem ou framework em específico. Porém, para fins de exemplo, vamos a partir de agora falar mais especificamente da framework Spring, a qual citei um pouco mais acima. No geral, tudo que veremos a seguir independe do próprio Spring pode ser aplicado a qualquer tecnologia ou framework web reativa, beleza?
Para melhor entendimento do funcionamento do esquema "tradicional" que temos de uma requisição uma thread, veremos uma imagem que deve ilustrar como esse esquema funciona:
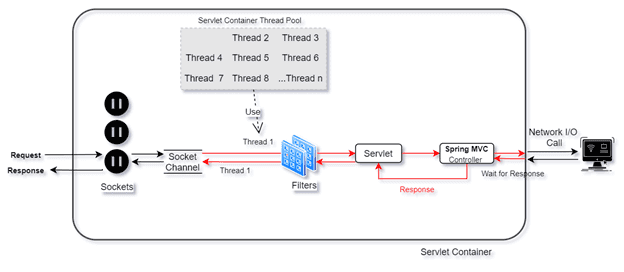
Observe que a imagem acima detalha o esquema de uma thread uma requisição até em nível de sistema operacional, observe onde temos ali os "Sockets". Observe também os "Filters" do Spring, responsável por delegar algum processo a requisição que chegou. Como estamos falando de bloqueio, a imagem acima mostra uma chamada de rede, que é um I/O.
O lugar onde temos que ter mais atenção é ali onde temos o "Wait for Response", que precede o retorno, ou seja, a resposta da chamada I/O, e a thread só é retornada ao Pool de Threads do Servlet Container ao fim de sua execução, antes de chegar ao "Socket Channel".
Isso mostra como perdemos capacidade de processamento, pois se por exemplos duas requisições chegarem, uma que vai realizar uma chamada I/O de rede que levará 2 segundos e uma chamada a um cache que está na memória da aplicação que levaria 5 milissegundos, se tivéssemos apenas 1 thread disponível a chama de 5 milissegundos a página cache demoraria os 2 segundos a mais da chamada anterior, fazendo a CPU ficar ociosa por 2 segundos.
Talvez ao vermos o cenário acima acreditemos ser algo absurdo, por exemplo, termos 2 requisições e 1 thread apenas no pool de threads. E realmente é se pensarmos em algo para o ambiente produtivo! Mas se aumentarmos para um cenário 2000 requisições simultâneas e um pool de threads de 10, ou até mesmo 100, acredita mesmo que o cenário acima não deva ocorrer? Eu não apostaria nisso 🤭. Inclusive, são esses cenários que levam uma aplicação a retornar 503, Service Unavailable Error.
Agora que vimos como funciona o esquema à moda antiga, vamos dar uma olhada nessa tal de programação reativa.
Modelo assíncrono e o Event Loop
O desenho abaixo mostra de forma simples como esse esquema funciona. Basicamente nós temos o Socket Channel recebendo e passando para o EventLoop as requisições que chegam para serem processadas. Depois, cada uma dessas requisições que pararam no EventLoop são delegadas para suas funções, muitas vezes I/O.
Observe o esquema abaixo:
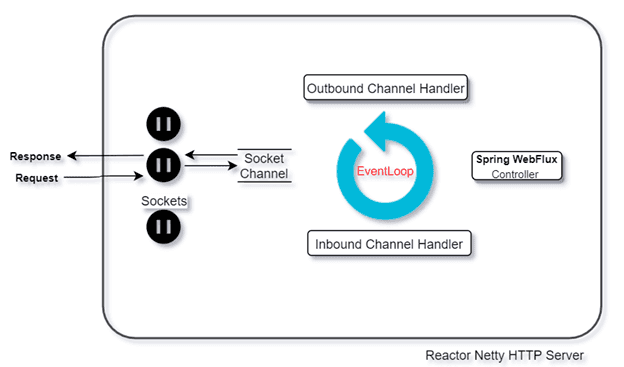
Um detalhe interessante e importante que vale ressaltar nessa imagem acima é que na base da imagem temos o "Reactor Netty Http Server". Esse é o servidor de aplicação web java capaz de suportar transações reativas, diferentemente do Tomcat. Sem ele, todo o framework de programação reativa não teria valor ou não teria seu ganho máximo. A programação reativa não tem que ser aplicada apenas "no núcleo", apenas na forma de programar ou no servidor de aplicação web, tem que ser aplicada a tudo pois caso não, como eu falei antes, não temos seu real proveito! Até por isso vimos toda a parte de sistemas operacionais acima que é o que viabiliza essa economia de recursos.
Na imagem abaixo nós já temos uma imagem mais precisa, com mais detalhes de como funciona esse esquema de programação reativa dentro do framework Spring. Observe a imagem abaixo para dissecarmos mais sobre ela:
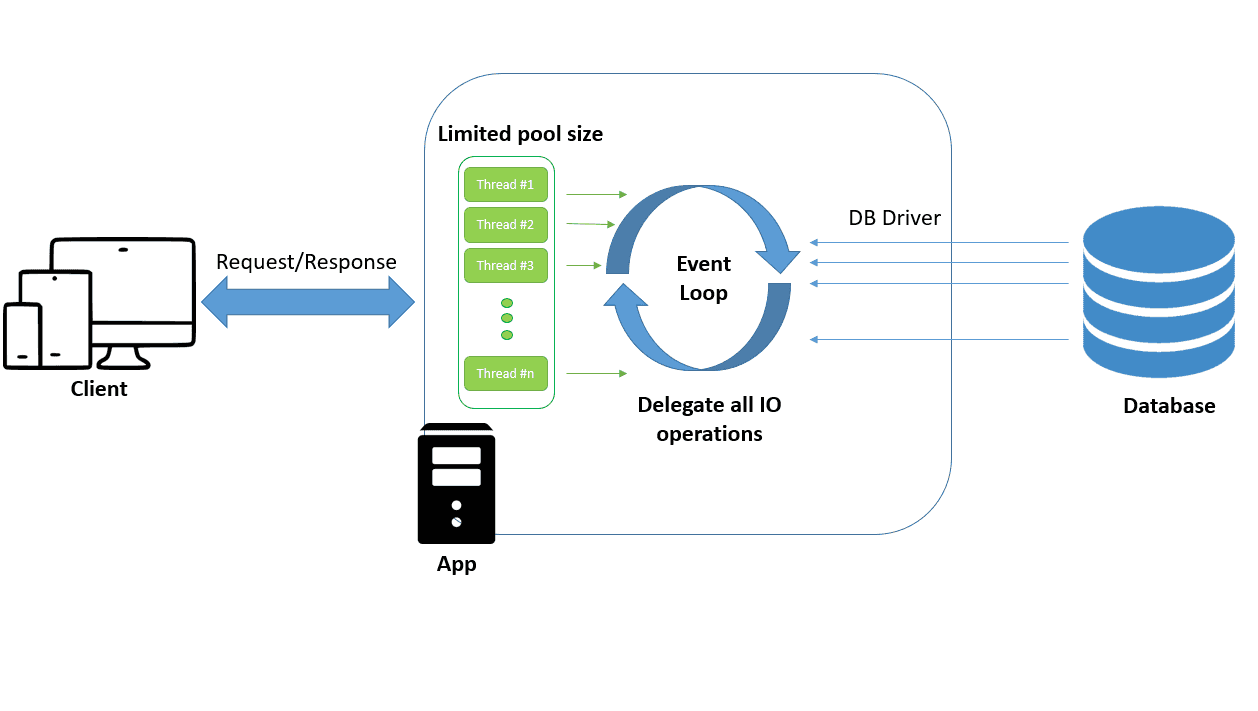
Temos um pool de threads que é responsável por receber todas as requisições que chegam do Socket Channel. Ela passa para o EventLoop que está em constante execução recebendo todas as threads que tem alguma operação a ser executada e passa para frente, que no caso do exemplo da imagem é uma chamada de I/O feita para um banco de dados.
A thread responsável por receber e responder a requisição Web terá uma atuação bem pequena, pois só recebe e repassa para o EventLoop a solicitação de operação, por isso que sempre vamos ter muitas threads disponíveis para receber e responder nossas requests. E teremos o EventLoop que, quando uma operação I/O finalizar, ela recebe uma thread do pool para responder e assim evita que essa thread fique parada todo o tempo que o I/O precisar para processar o solicitado.
Conclusão
Nesse artigo nós vimos como funciona a programação reativa dentro do sistema operacional, fomos no coração do funcionamento e vimos uma descrição da sacada que foi implementar um conjunto de threads em um pool para extrair o máximo da máquina e dar poder a nossa aplicação. Apesar de uma boa introdução e entendimento de como funciona esse esquema, precisamos entender o ganho que temos e isso nós veremos ver na parte 2 que vou escrever desse artigo com uma analogia a uma cozinha. Nos vemos lá também?
Referências
- https://elo7.dev/programacao-reativa-parte-4/
- https://dzone.com/articles/spring-webflux-eventloop-vs-thread-per-request-mod
- https://www.treinaweb.com.br/blog/o-que-e-programacao-reativa
Livro: SISTEMAS OPERACIONAIS MODERNOS, Andrew S. Tanenbaum e Herbert Bos (Autor) 4º Edição
